What Is a Decentralized Search Engine? How Desearch Is Building Search on Bittensor

Decentralized search engines work differently from traditional ones by distributing tasks like data collection, indexing, and ranking across a network of independent participants. Instead of relying on a single company, contributors compete to deliver accurate and relevant search results, earning rewards for quality work. This approach prioritizes transparency, removes single points of failure, and allows greater access to real-time data, especially useful for developers and AI systems.
Desearch, operating on the Bittensor network as Subnet 22, is a decentralized search engine designed to provide structured, real-time data from sources like X (formerly Twitter), Reddit, and Arxiv. It uses miners to gather and process data, validators to score and rank results, and an incentive system to reward top performers. This model eliminates reliance on expensive and restrictive centralized APIs, offering a cost-effective, scalable solution for developers needing up-to-date information.
Key highlights:
- How it works: Distributed miners collect and process data; validators assess quality using on-chain consensus.
- Advantages: Open-source, transparent ranking, no single point of control, and lower costs.
- Use case: Developers can access structured data via a single API for AI systems, research tools, and retrieval-augmented generation (RAG) pipelines.
Desearch exemplifies how decentralized systems can reshape search infrastructure for AI and software development by offering real-time, unbiased, and efficient data access.
What Is a Decentralized Search Engine?
A decentralized search engine operates through a distributed network where independent participants handle data collection, indexing, and ranking - tasks traditionally managed by a single company. Instead of relying on a centralized organization to run all servers, these responsibilities are spread across multiple nodes, each managed by different individuals or entities.
In this system, contributors compete to deliver the most relevant and accurate search results. They gather, organize, and process data, which is then reviewed by validators - other participants who assess the quality of the results based on criteria like relevance, timeliness, and completeness. Contributors who consistently meet high standards are rewarded with tokens, while those who underperform risk being removed from the network.
This model offers several benefits. For one, it enhances transparency since ranking algorithms and performance metrics are often open-source and accessible to the public, unlike proprietary systems. It's also more resilient, as the network doesn't rely on a single point of failure - if one node goes offline, others seamlessly take over. Additionally, the system promotes fairness by allowing anyone with the right resources and skills to participate, creating a merit-based environment. These features collectively enable an incentive-driven approach to maintaining quality.
Rather than enforcing strict rules, the system uses rewards to encourage high-quality contributions.
This reward-based structure ensures that participants are naturally motivated to align their efforts with the network's goals. Those who consistently deliver top-tier results earn full rewards, creating a self-sustaining economy where quality directly translates to compensation.
Unlike traditional search engines that often prioritize business interests or paid advertisements, decentralized search engines rely on peer-reviewed methods to provide unbiased results. Built on peer-to-peer technology, these systems use immutable and peer-verified frameworks to ensure trust and reliability.
How Centralized Search Engines Work
Centralized search engines are controlled by single corporations that oversee the entire search process using proprietary systems. Here's how it works: automated bots, often called crawlers, scan the web and gather content. This content is then stored in a central database, where algorithms - essentially secret formulas - determine how search results are ranked. These algorithms rely on hidden metrics to evaluate relevance and authority, but they don't offer any transparency to users or developers.
The business model for these search engines often revolves around targeted advertising, which frequently involves tracking user data. Another revenue stream comes from charging developers hefty fees for API access. Giga, the founder of Desearch, highlights the challenges developers face in this system:
Every useful API was either locked down, rate-limited, or too expensive to use at scale.
This creates a major hurdle for AI developers and researchers who need real-time data to build and refine their tools.
But the issues don't stop at cost. Developers often find themselves locked into one provider's ecosystem, leaving them vulnerable to sudden changes in terms and conditions. This dependency creates instability for third-party applications. Additionally, centralized search engines act as gatekeepers of information, raising concerns about bias and censorship. Giga points out:
Search is one of the most important tools we have online, but it's mostly hidden behind closed APIs.
Because users and developers can't see how search results are filtered or ranked, there's no way to verify the fairness or quality of the information provided. These challenges highlight the need for decentralized alternatives, which aim to distribute control across independent participants rather than concentrating it in the hands of a single entity.
How Decentralized Search Works Differently
::: @figure 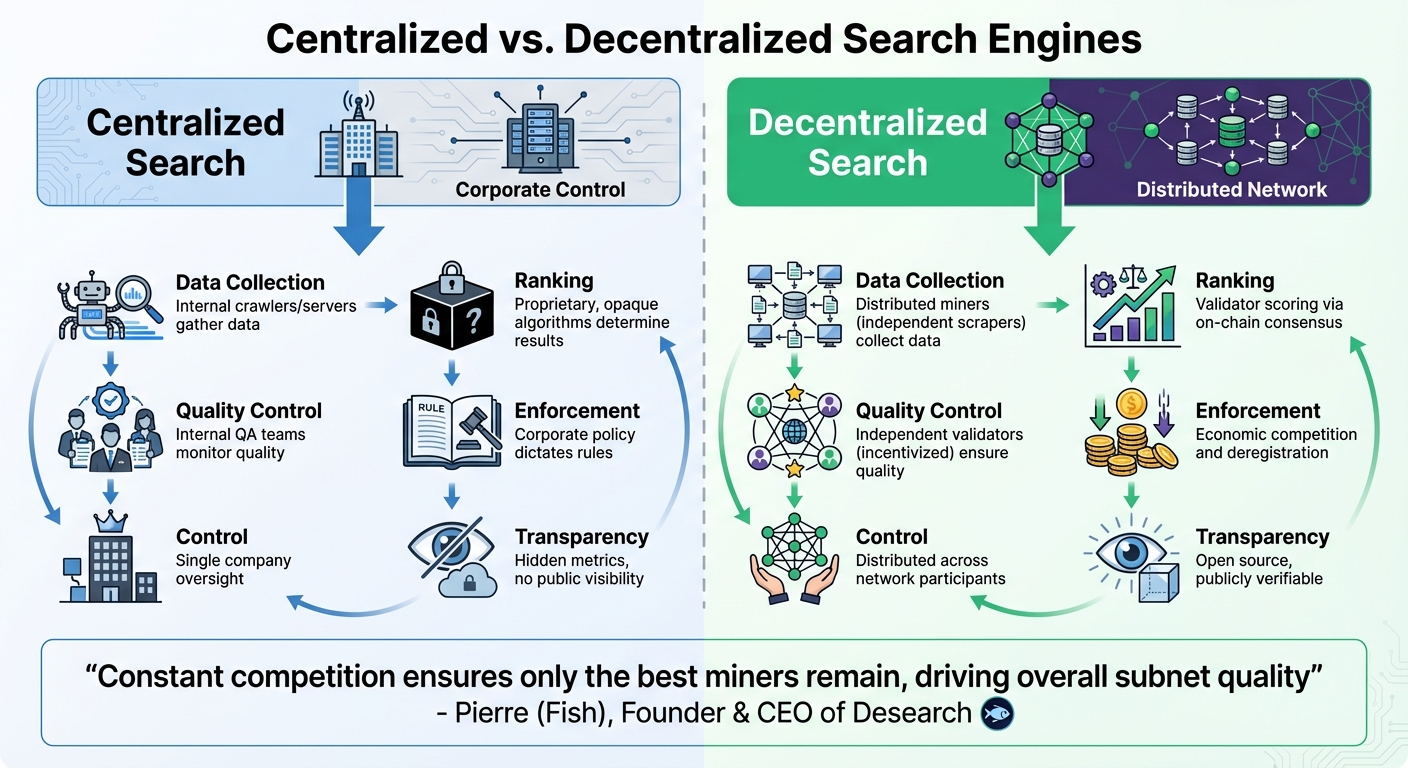 {Centralized vs Decentralized Search Engine Architecture Comparison}
{Centralized vs Decentralized Search Engine Architecture Comparison}
Decentralized search takes a fresh approach by spreading responsibilities across a network of independent participants, rather than placing them in the hands of a single company. In this model, data collection and processing are carried out by independent miners. These miners gather and index information in real time from sources like X (formerly Twitter), Reddit, and the broader web. They then use large language models to analyze this raw data and create summaries tailored to specific search queries.
Instead of relying on corporate teams for quality control, the decentralized system introduces independent validators. These validators test the accuracy of results by running synthetic queries and determine rankings through an on-chain consensus mechanism called the Yuma Consensus. Unlike the proprietary algorithms used in traditional search engines, rankings here are shaped by validator scores processed through this consensus system, which also dictates how rewards are distributed.
The system enforces quality through competition rather than corporate policies. Miners compete for rewards, and only the highest-performing ones stay active. Underperformers are deregistered and replaced by new participants. Pierre (Fish), founder and CEO of Desearch, explains:
Constant competition ensures only the best miners remain, driving overall subnet quality.
This competitive structure naturally raises the network's standards over time, creating a system where incentives drive continuous improvement.
| Responsibility | Centralized Model | Decentralized Model |
|---|---|---|
| Data Collection | Internal crawlers/servers | Distributed miners (independent scrapers) |
| Ranking | Proprietary, opaque algorithms | Validator scoring via on-chain consensus |
| Quality Control | Internal QA teams | Independent validators (incentivized) |
| Enforcement | Corporate policy | Economic competition and deregistration |
Transparency is another key feature of decentralized search. Since the system is open source and validator logs are publicly available, anyone can see how miners are scored and what content they produce. This openness replaces the "black box" algorithms of centralized search engines with processes that are verifiable and auditable by anyone. The clear distribution of responsibilities highlights how decentralized search is built on fundamentally different principles compared to its centralized counterpart.
What Is Desearch?
Desearch is a decentralized search engine tailored for developers and AI agents that require real-time data. Operating as Subnet 22 on the Bittensor network, it offers a unified API endpoint that pulls structured data from high-value sources like X (formerly Twitter), Reddit, Arxiv, and the open web. Unlike traditional search engines that depend on massive centralized indexes, Desearch brings together independent data providers that compete to deliver timely and relevant results. This decentralized setup not only simplifies data collection but also meets the growing demand for real-time information.
The platform is designed to address a significant challenge for modern AI systems: access to up-to-date data. As Giga, the founder of Desearch.ai, explains:
Subnet 22 solves the problem of AIs being 'blind' without live data by enabling miners to scrape, analyze, and rank information... returning fresh, relevant, and contextually accurate results.
What sets Desearch apart is its ability to go beyond providing links. By leveraging large language models, it analyzes content and delivers concise, context-rich summaries. This makes it especially useful for AI agents and retrieval-augmented generation (RAG) pipelines, which rely on current, accurate information to function effectively.
The decentralized nature of Desearch ensures there's no single point of control or failure. Independent miners use their own APIs and indexing tools to perform real-time searches. Additionally, the system is open source under an MIT license, allowing anyone to review and verify the data retrieval and ranking processes.
What Is the Bittensor Network?

Bittensor is an open-source, decentralized network aimed at creating digital commodities like AI inference, computational power, and data processing. Instead of depending on a centralized entity to manage its infrastructure, the network distributes tasks among independent participants. These contributors are rewarded based on the quality of their work, encouraging a competitive and efficient system.
The network is organized into subnets - individual marketplaces that focus on specific tasks, such as protein folding, financial forecasting, or search functionality. Within these subnets, miners generate the digital commodities, while validators assess the quality of their outputs. To incentivize contributions, Bittensor uses its native cryptocurrency, TAO (τ), rewarding participants in proportion to their performance.
"Each subnet is an incentive-based competition marketplace that produces a specific kind of digital commodity related to artificial intelligence. It consists of a community of miners who produce the commodity, and a community of validators who measure the miners' work to ensure its quality." – Bittensor Documentation
One notable example is Desearch, which operates as Subnet 22 within the Bittensor network. This subnet is dedicated to decentralized search and information retrieval. Instead of relying on a central server, its search infrastructure is powered by a distributed network of miners. These miners scrape and index data, while validators evaluate the relevance and accuracy of the results. Subnet 22 focuses on processing real-time data from platforms like X (Twitter), Reddit, Arxiv, and other parts of the web. This collaborative approach highlights how decentralized search is orchestrated within the network.
The reward system ensures that only high-performing miners thrive. Miners delivering accurate and timely results earn more TAO, while those who underperform risk being replaced. This performance-driven model helps maintain the quality and reliability of the network.
How Subnet 22 Works
Subnet 22 operates through a well-coordinated system involving three main components: miners for gathering data, validators for assessing its quality, and an incentive mechanism to reward top performers.
Miners (Data Providers)
Miners are independent data providers tasked with collecting, indexing, and processing real-time data from platforms like X (formerly Twitter), Reddit, Arxiv, and Google. When a search query is received, miners utilize APIs and indexing tools to locate relevant information. They then employ large language models to transform raw data into concise summaries. Success in this role requires miners to maximize API efficiency - especially for platforms like Twitter - and ensure their summaries are both accurate and thorough.
"The vision is to incentivize miners who excel in scraping and indexing multiple databases, retrieving that data quickly, and using a language model to accurately summarize raw data."
This vision, as described by Pierre (Fish), the Founder and CEO of Desearch, emphasizes the importance of speed, precision, and comprehensive data handling. New miners are given an immunity period of 4,096 blocks (approximately 13.7 hours) to develop their performance before they risk deregistration. Subnet 22 typically accommodates 256 UID slots, with around 192 reserved for miners.
Validators
After miners submit their processed data, validators take over to evaluate its quality. Using large language models, validators score miner responses against specific search queries. The evaluation process is based on three weighted criteria:
- Twitter Scoring (50%): Focuses on the relevance and depth of information in 10 submitted Twitter links.
- Summary Scoring (40%): Assesses how well the summary aligns with the original query, emphasizing clarity, depth, and precision.
- Search Scoring (10%): Measures the relevance and engagement of general web links in addressing the query.
In addition to these content-focused metrics, validators also consider technical aspects like response speed, data freshness, and structural consistency. All validator logs and miner scores are accessible through the Weights and Biases platform, ensuring transparent community monitoring.
| Scoring Component | Weight | Key Evaluation Criteria |
|---|---|---|
| Twitter Scoring | 50% | Relevance of 10 submitted links, depth of information, and answer directness |
| Summary Scoring | 40% | Relevance to the prompt, depth, comprehensiveness, clarity, and precision |
| Search Scoring | 10% | Relevance of web links and engagement with keywords and themes |
This scoring system ensures that only the most reliable and high-quality data contributes to the network.
Incentive Mechanism
Subnet 22 rewards miners based on their performance scores, with higher scores leading to greater TAO earnings. Miners who underperform are replaced once their immunity period ends. During each cycle, the miner with the lowest emissions score is deregistered and replaced by a new participant. This ongoing pruning process, combined with transparent performance tracking via Weights and Biases, drives continuous improvement. Over time, miners refine their strategies to compete with top performers, keeping the network aligned with its quality standards.
Why Incentives Matter in Search
Rules alone can't guarantee high-quality search results in decentralized systems. Without centralized oversight, static rules become easy to exploit, often leading to unreliable or low-quality data. Traditional administrative controls simply don't scale when dealing with a distributed network of independent contributors.
That's where incentives come into play. Incentive mechanisms solve this problem by aligning individual goals with the overall health of the network. When contributors, or miners, earn TAO tokens based on the quality of their work, they're naturally motivated to perform better. For instance, the Bittensor network rewards participants with TAO tokens in proportion to the value they bring: "The Bittensor network constantly emits liquidity, in the form of its token, TAO, to participants in proportion to the value of their contributions." This creates a feedback loop where higher-quality results lead to bigger rewards, encouraging ongoing improvement.
Competition plays a key role here. Only the top-performing miners remain active, as the system rewards those who consistently refine their methods. By analyzing transparent performance data, miners can improve their API calls, data retrieval processes, and summarization techniques, all in pursuit of better scores and greater rewards.
Open Source by Design
Desearch Subnet 22 is built with a fully open source philosophy, licensed under MIT. Its entire codebase is publicly accessible at https://github.com/Desearch-ai/subnet-22, inviting anyone to explore, fork, and contribute to the project. The repository highlights active community involvement, with numerous commits, stars, and forks showcasing its engagement.
This open framework eliminates the barriers often found in centralized search systems. Developers can dive into every aspect of the system - examining data collection processes, scoring mechanisms, and more. Nothing is hidden behind proprietary algorithms or locked systems. As Giga, the founder of Desearch.ai, puts it:
I wanted to build something transparent - where anyone can look under the hood, run part of it, and make it better. No fancy terms, no gatekeeping - just open access to data.
This commitment to transparency embodies the decentralized principles at the heart of Desearch's design.
But the openness doesn't stop at code. Validator logs, including miner scores and related content, are fully accessible through Weights and Biases (wandb). This allows for real-time, verifiable insights into the incentive mechanisms, enabling miners to track their performance, compare it with top contributors, and refine their strategies.
For developers, this level of openness means flexibility and ease of integration. By cloning the repository with git clone https://github.com/Desearch-ai/subnet-22.git, they can embed decentralized search functionality into AI agents or retrieval-augmented generation (RAG) pipelines. It acts as a foundation for creating custom research tools, monitoring applications, or even new search interfaces - all without licensing fees.
The open source model also drives innovation through community collaboration. Instead of relying on the vision of a single company, the project evolves with contributions from miners, validators, and developers around the globe. Validators can use the run.sh script to enable automatic updates, ensuring their nodes always run the latest, community-verified code. This collaborative approach aligns perfectly with the decentralized philosophy, where no single entity dictates the infrastructure's direction or access. By embracing open source, Desearch not only simplifies integration but also fosters ongoing innovation within the decentralized search ecosystem.
How Developers Use Desearch
Developers interact with Desearch through a single API endpoint, simplifying the process of querying multiple platforms like X, Reddit, and Arxiv. Instead of juggling separate API keys, they send queries to a unified interface and receive structured, ranked results in return. This streamlined approach integrates effortlessly with the decentralized search architecture described earlier.
Here's how it works: A developer submits a query - say, "What is augmented reality's daily impact in 2024?" - to the Desearch API. Miners then gather relevant content, while validators use large language models (LLMs) to score and rank the results. The developer ultimately receives a structured JSON response containing ranked links, sentiment analysis, and metadata such as retweet counts or timestamps.
This setup eliminates much of the usual infrastructure hassle. Developers no longer need to worry about building or maintaining scraping systems, managing rate limits, or cleaning up raw data. The decentralized network of miners takes care of data collection and indexing, while validators handle ranking and verification using AI. Thanks to miner parallelism, the system supports thousands of requests per second, scaling effortlessly without requiring developers to manage additional resources.
Why Decentralized Search Matters for AI
Decentralized search, as exemplified by Desearch, is reshaping how AI systems operate by addressing a critical challenge: access to real-time external data. Modern AI systems, especially large language models and AI agents, depend on up-to-date information to function effectively in dynamic environments. Without this, they're stuck relying on outdated training data, which severely limits their usefulness in making timely decisions.
Centralized APIs, while commonly used, come with strict rate limits that restrict the high-volume data flows AI systems require. On top of that, enterprise-level access to these APIs can be prohibitively expensive, making large-scale AI operations financially out of reach for many developers.
"Search isn't a feature anymore. It's infrastructure. If your product depends on real-world data, how you search determines how fast and how smart it can move."
– Desearch.ai
This shift in thinking transforms search from a mere tool into a foundational component of AI workflows. Decentralized search solves the limitations of centralized APIs by offering unrestricted, real-time data access at a fraction of the cost. Built on the decentralized architecture of Subnet 22, it provides structured, decision-ready results tailored for Retrieval-Augmented Generation (RAG) pipelines and AI workflows.
Scalability is another key advantage. Centralized systems often hit hard limits on request volumes, but decentralized networks rely on distributed processing to handle thousands of requests per second - without requiring developers to manage additional infrastructure.
The Future of Search
Search has evolved into a critical backbone for accessing real-world data. As the demand for real-time information grows, search engines are being reimagined to deliver not just results, but actionable insights that fuel modern AI systems and applications.
Why this shift? Static AI models have a major flaw - they're stuck in time. Once their training ends, they start to lag behind the ever-changing world. Real-time search bridges this gap by streaming live data from platforms like X, Reddit, and the open web directly into AI workflows. This makes search a core building block for how quickly and effectively applications can adapt to new information. In this new landscape, search doesn't just support decision-making - it powers it.
Desearch and Subnet 22 are already showcasing this future in action. By late 2025, Desearch had proven its scalability and affordability, offering an API that costs 16 times less than traditional centralized options. It delivers real-time, structured data tailored for AI agents and retrieval-augmented generation (RAG) pipelines. Built on open-source principles and powered by the Bittensor network, Desearch exemplifies how decentralized systems can outperform centralized ones - not through empty promises, but through measurable, transparent results. Together, Desearch and Subnet 22 highlight how decentralized models are reshaping search infrastructure for AI and software development.